1. 背景
Flash 设备存在如下缺点
- 存在坏块
- 使用寿命较短
- 存储介质不稳定(bitflip)
- 读写速度慢
- 只能通过擦除将0改成1
- 最小读写单位为page or sub-page
Kernel 引入UBI (Unsorted Block Images)来解决这些问题。UBI 本身就是针对RAW Flash的一个卷管理系统,并且提供基于磨损均衡的逻辑到物理的映射。它类似于LVM(Logical Volume Manager)

因此UBI 具有如下特点:
- UBI provides volumes which may be dynamically created, removed, or re-sized
- UBI implements wear-leveling across whole flash device
- UBI transparently handles bad physical eraseblocks;
- UBI minimizes chances to lose data by means of scrubbing. (针对Nand Flash 的bit flip现象,将有bit-flips的数据块移动到好的数据块上)
2. 框架
在kernel MTD 模块看来, UBI 子系统的框架如下图: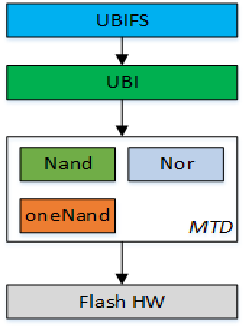
UBI 子模块的文件组织结构如下图: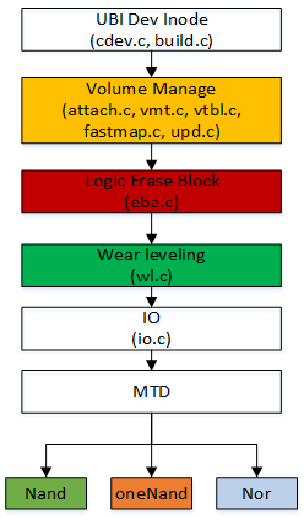
| 文件名 | 说明 |
|---|---|
| cdev.c | 字符设备节点访问操作, attach/detach MTD, volume add/remove/rename/resize |
| build.c | /dev/ubictrl, /sys 等节点注册 |
| attach.c | attach MTD sub-system |
| vmt.c | volume 逻辑操作,增删, 重命名, 重新设定size |
| vtbl.c | vmt.c 的下层,实际操作读写 |
| fastmap.c | 支持快速扫描MTD 设备 |
| upd.c | update volume, 考虑到突然掉电等引起的更新错误 |
| eba.c | Erase Block Association sub-system 子系统, 逻辑映射 |
| wl.c | wear-leveling sub-system 磨损均衡子系统 |
| io.c | 与MTD 设备I/O 交互, R/W data, VID(volume ID)/EC(Erase Counter) header |
| kapi.c | 向UBIFS 提供的api 接口 |
3. 代码分析
3.1. 数据结构
3.1.1. UBI Headers
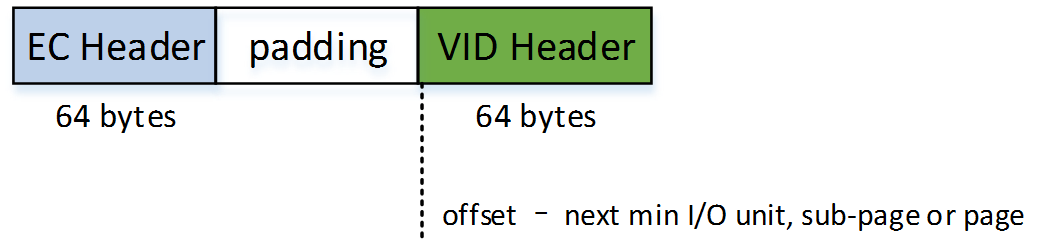
UBI 包含两个被CRC32 保护的64 bytes header在每一个非坏块的开始:
- erase counter(EC) header
- volume identifier(VID) header
因此,LEB < PEB 就是因为存储了UBI headers.
参见 drivers/mtd/ubi/ubi-media.h1
2
3
4
5
6
7
8
9
10
11struct ubi_ec_hdr {
__be32 magic;
__u8 version;
__u8 padding1[3];
__be64 ec; /* Warning: the current limit is 31-bit anyway! */
__be32 vid_hdr_offset;
__be32 data_offset;
__be32 image_seq;
__u8 padding2[32];
__be32 hdr_crc;
} __packed;
每一次Erase 都会将EC 值增加。在unclean reboot 发生或者数据被corrupted, EC 将会被写入attach MTD 设备扫描的EC average。
1 | struct ubi_vid_hdr { |
EC header 存储offset 为0, 而VID header 存储offset 为next min I/O Unit, sub-page or page.
- NOR Flash, min I/O 为 1 byte, VID header offset 为64
- Nand Flash, sub-page or page
3.1.2. volume table
数据是存储在flash 设备上, volume table 是ubit_vtbl_record 的数组,每一个记录它包含了如下meta-data:
- 卷名
- 保留物理擦除快的数量
- 类型(static or dynamica)
- crc 校验
- update marker(用于标记更新volume name or size)
1 | struct ubi_vtbl_record { |
UBI 使用了两个逻辑擦除快(Logical EraseBlock)保存record 数据,LEB0 and LEB1. 他们两者相互拷贝,以此来保证突发事件例如掉电等异常情形。当attach MTD 设备时,UBI确保这两个volume table是相同的,否则上次可能是unclean boot导致,使用新的,无corrupted data 拷贝到另一块。
UBI 需要维护三种table:
- volume table
- eraseblock association(EBA) table
- erase counter(EC) table
volume table 是存储在Flash 上,它的修改只会发生在create, delete, re-size 时。
EBA table 是用于logical to phsical 映射关系。
EC table 包含每个PEB 的erase conter 值, UBI wear-leveling 将会使用此表格。
EBA, EC table 可以做到存储在flash 上,但是它需要journaling, journal replay, journal commit 等,在boot-loader 时保证简单,代码的size 是不太容易的。
因此, EBA, EC table 默认在attach MTD 时,根据扫描的EC,VID header 信息在RAM 中构建.
在vid_hdr 中包含的vol_id, lnum, squm 指定了他们的volume_id, squm 序列号, lnum 逻辑num 号, UBI attach 子系统在attach 时,根据这些信息创建red-block tree, 就能顺序读取data。
3.2. UBI Sub-system
3.2.1. attach mtd
本质是扫描(scan_all or scan_fast(fastmap))MTD 设备上的EC、VID header 信息生成volume 等结构体。
相关的数据接口如下: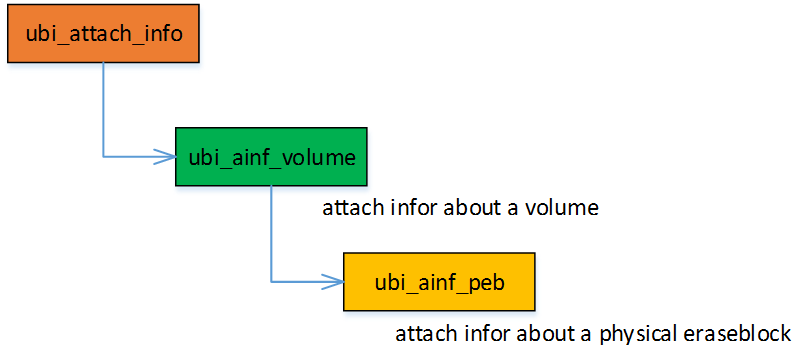
ubi_ainf_peb -> ubi_ainf_volume.rb -> ubi_attach_info.volume。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49struct ubi_attach_info {
struct rb_root volumes;
struct list_head corr;
struct list_head free;
struct list_head erase;
struct list_head alien;
int corr_peb_count;
int empty_peb_count;
int alien_peb_count;
int bad_peb_count;
int maybe_bad_peb_count;
int vols_found;
int highest_vol_id;
int is_empty;
int min_ec;
int max_ec;
unsigned long long max_sqnum;
int mean_ec;
uint64_t ec_sum;
int ec_count;
struct kmem_cache *aeb_slab_cache;
};
struct ubi_ainf_volume {
int vol_id;
int highest_lnum;
int leb_count;
int vol_type;
int used_ebs;
int last_data_size;
int data_pad;
int compat;
struct rb_node rb; /* link in the volume RB-tree */
struct rb_root root;
};
struct ubi_ainf_peb {
int ec;
int pnum; /* physical eraseblock number */
int vol_id; /* ID of the volume this LEB belongs to */
int lnum; /* logical eraseblock number */
unsigned int scrub:1;
unsigned int copy_flag:1;
unsigned long long sqnum;
union {
struct rb_node rb; /* link in the per-volume RB-tree of &struct ubi_ainf_peb objects */
struct list_head list;
} u;
};
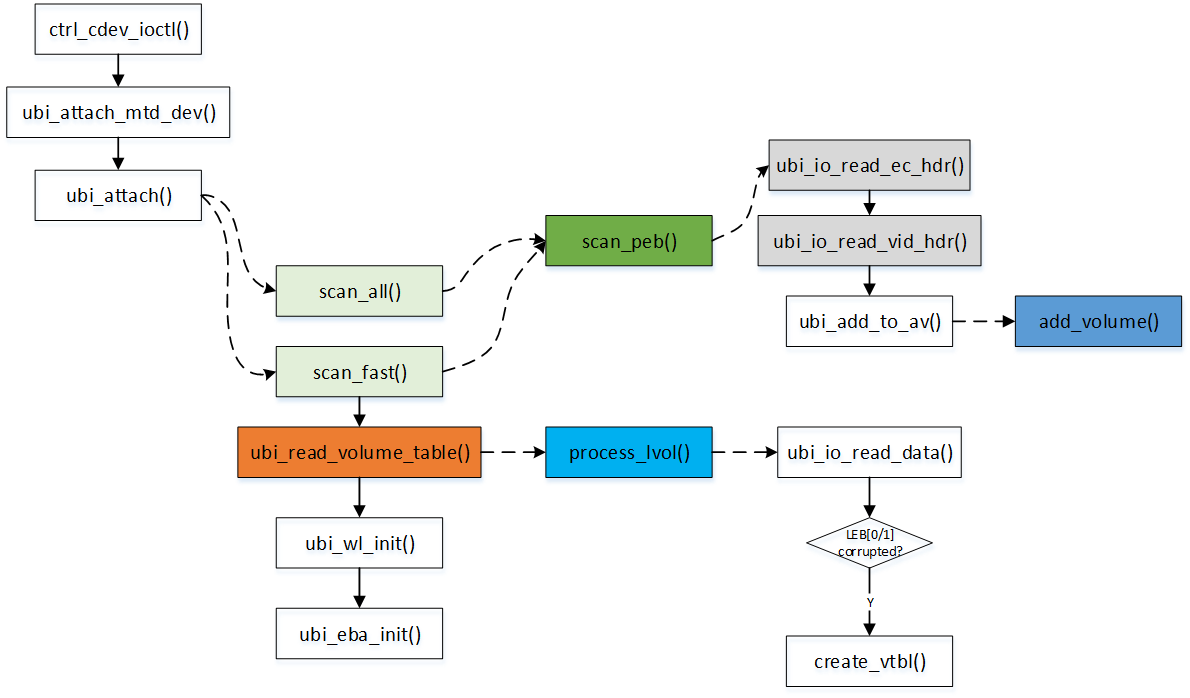
scan_all() 扫描每一个peb 并读取其中的ec_hdr, vid_hdr。 这里分层了三层结构体:
- ubi_attach_info
- ubi_ainf_volume
- ubi_ainf_peb
管理volume, 以及属于该volume 的全部pebs 分类清晰,便于管理。
ubi_read_volume_table() 会在RAM 中生成volume table record. 他们是存放在具体的vol_id 的前两个LEB[0,1]中, 在process_lvol() 读取数据,并检查是否数据污染。
3.2.2. eba, eraseblock association
在attach 时候, 调用ubi_eba_init(), UBI EBA 子系统会根据数据结构 ubi_attach_info -> ubi_ainf_volume -> ubi_ainf_peb, 在ubi_ainf_peb 里面记录了pnum, lnum,这就是物理逻辑映射关系。
1 | int ubi_eba_init(struct ubi_device *ubi, struct ubi_attach_info *ai) |
后续的write, read 都是通过在RAM 中的eba_tlb 进行逻辑查询后,再调用到io -> mtd.read/write
假如EBA 没有映射, 调用Wear-leveling 子系统获取PEB。
至于lnum 的值在UBIFS 中体现,是从上层下来。UBI wear-leveling 会考虑磨损均衡的情况下选择合适的PEBs 映射到某一个lnum 上。
marking eraseblocks as bad
判断依据:
- 写操作时失败,UBI 将数据搬移,并准备对该eraseblock 进行torturing(拷问,审查)。
- erase 操作失败EIO error, 直接将它标记为bad
torturing 主要是两方面
- eraseblock, and read check all is 0xFF
- write data, and read check
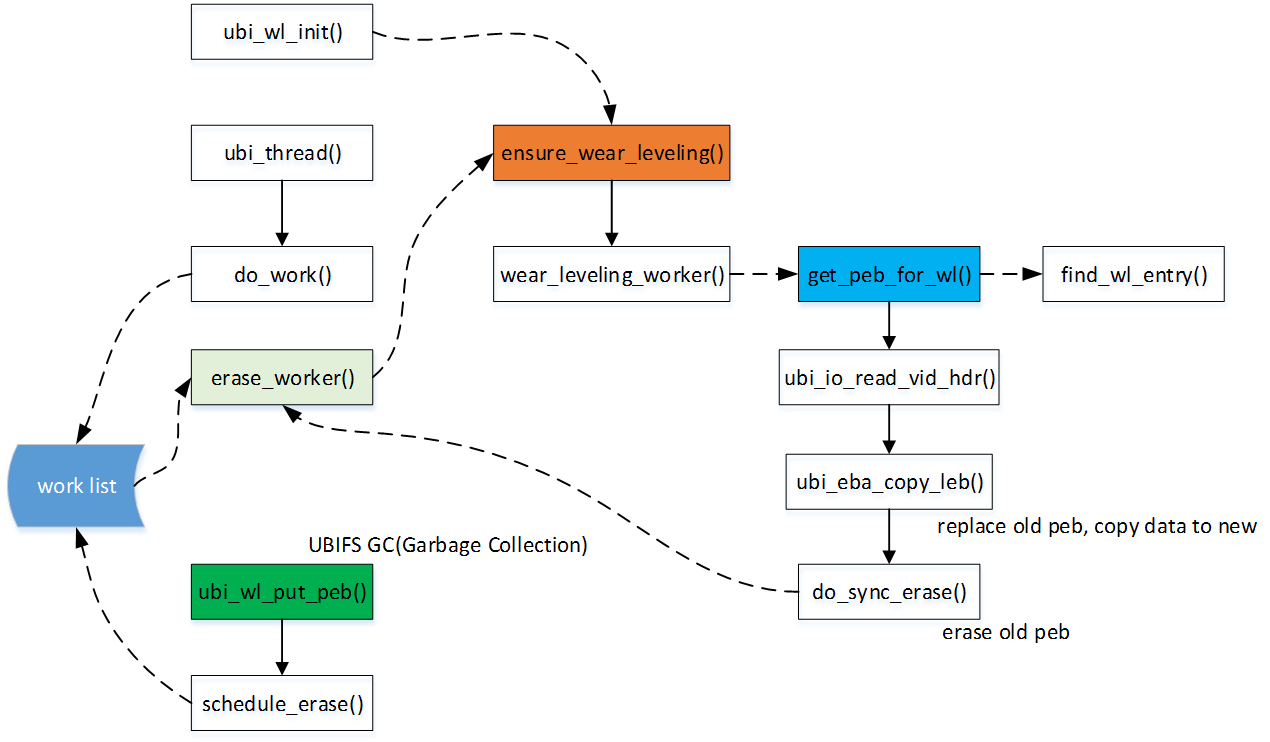
3.2.3. wear-leveling
磨损均衡是UBI的核心功能之一,负责管理PEB的分配、回收、擦除、scrub、磨损均衡等, 在这些操作时都会触发磨损均衡检查。其中scrub、擦除, 磨损均衡功能由UBI后台线程进行异步调度管理。
1
2
3
4
5
6
7
8struct ubi_wl_entry {
union {
struct rb_node rb; /* link in the corresponding (free/used) RB-tree*/
struct list_head list;
} u;
int ec;
int pnum;
};
如果used peb 的EC 与free peb 的EC 差大于 UBI_WL_THRESHOLD 则会考虑使用wear-leveling 子系统进行磨损均衡搬移,避免过多的搬移数据造成本身的反复擦除。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97static int wear_leveling_worker(struct ubi_device *ubi, struct ubi_work *wrk,
int shutdown)
{
int err, scrubbing = 0, torture = 0, protect = 0, erroneous = 0;
int vol_id = -1, uninitialized_var(lnum);
struct ubi_wl_entry *e1, *e2;
struct ubi_vid_hdr *vid_hdr;
vid_hdr = ubi_zalloc_vid_hdr(ubi, GFP_NOFS);
mutex_lock(&ubi->move_mutex);
spin_lock(&ubi->wl_lock);
if (!ubi->scrub.rb_node) {
/*
* Now pick the least worn-out used physical eraseblock and a
* highly worn-out free physical eraseblock. If the erase
* counters differ much enough, start wear-leveling.
*/
e1 = rb_entry(rb_first(&ubi->used), struct ubi_wl_entry, u.rb);
e2 = get_peb_for_wl(ubi);
if (!(e2->ec - e1->ec >= UBI_WL_THRESHOLD)) {
dbg_wl("no WL needed: min used EC %d, max free EC %d",
e1->ec, e2->ec);
/* Give the unused PEB back */
wl_tree_add(e2, &ubi->free);
ubi->free_count++;
goto out_cancel;
}
rb_erase(&e1->u.rb, &ubi->used);
dbg_wl("move PEB %d EC %d to PEB %d EC %d",
e1->pnum, e1->ec, e2->pnum, e2->ec);
} else {
/* Perform scrubbing */
scrubbing = 1;
e1 = rb_entry(rb_first(&ubi->scrub), struct ubi_wl_entry, u.rb);
e2 = get_peb_for_wl(ubi);
rb_erase(&e1->u.rb, &ubi->scrub);
dbg_wl("scrub PEB %d to PEB %d", e1->pnum, e2->pnum);
}
ubi->move_from = e1;
ubi->move_to = e2;
spin_unlock(&ubi->wl_lock);
/*
* Now we are going to copy physical eraseblock @e1->pnum to @e2->pnum.
* We so far do not know which logical eraseblock our physical
* eraseblock (@e1) belongs to. We have to read the volume identifier
* header first.
*
* Note, we are protected from this PEB being unmapped and erased. The
* 'ubi_wl_put_peb()' would wait for moving to be finished if the PEB
* which is being moved was unmapped.
*/
err = ubi_io_read_vid_hdr(ubi, e1->pnum, vid_hdr, 0);
vol_id = be32_to_cpu(vid_hdr->vol_id);
lnum = be32_to_cpu(vid_hdr->lnum);
err = ubi_eba_copy_leb(ubi, e1->pnum, e2->pnum, vid_hdr);
/* The PEB has been successfully moved */
if (scrubbing)
ubi_msg("scrubbed PEB %d (LEB %d:%d), data moved to PEB %d",
e1->pnum, vol_id, lnum, e2->pnum);
ubi_free_vid_hdr(ubi, vid_hdr);
spin_lock(&ubi->wl_lock);
if (!ubi->move_to_put) {
wl_tree_add(e2, &ubi->used);
e2 = NULL;
}
ubi->move_from = ubi->move_to = NULL;
ubi->move_to_put = ubi->wl_scheduled = 0;
spin_unlock(&ubi->wl_lock);
err = do_sync_erase(ubi, e1, vol_id, lnum, 0);
if (e2) {
/*
* Well, the target PEB was put meanwhile, schedule it for
* erasure.
*/
dbg_wl("PEB %d (LEB %d:%d) was put meanwhile, erase",
e2->pnum, vol_id, lnum);
err = do_sync_erase(ubi, e2, vol_id, lnum, 0);
if (err)
goto out_ro;
}
mutex_unlock(&ubi->move_mutex);
return 0;
}
在EBA write 时,如果没有映射,我们就会调用ubi_wl_get_peb() 获取free PEB。
- drivers/mtd/ubi/wl.c *
ubi_wl_get_peb() ->
__wl_get_peb() ->
1 | int ubi_eba_write_leb(struct ubi_device *ubi, struct ubi_volume *vol, int lnum, |
3.2.4. fastmap
fastmap 利用存储在flash 上的fastmap volume 以此来加速attach。
fastmap 一般用于large flash, 例如4Gib Nand chips。
是否启用fastmap, 需要考虑到fastmap 本身会占用一些PEB,并且fastmap pool full, volume layout change or detach时,fastmap都需要写入信息到保留的PEB 中。
fastmap volume中存储的信息有:
- erase value
- a list of all PEBs and their state
- a list of all volumes and their EBA
- a list of PEBs called fastmap pool
fastmap 还有一个fastmap pool 概念, 它的size 大约为 5% of the total amount of PEBs。我们从fastmap pool 中取用PEBs,这样我们只需要关心fastmap pool 的PEBs, 而不用关心total PEBs, 减少了需要存储的信息量。