ubifs(Unsorted block images file system)之前本设计为jffs3,后改名为ubifs。
jffs2 本身设计是为small size NOR Flash。
他有如下缺点:
- index 是建立在RAM, 并且内存的消耗与Flash size 成线性关系
- mount 时间需要scan 整个Flash
但他有如下优点:
- 支持数据压缩
- 支持wear-leveling
- unclean reboot robustness(健壮性),jffs2 为LOGFS
因此ubifs 的需求有如下:
- 继承jffs2 的优点
- mem 消耗与Flash size 不是线性关系
- cache write (异步方式)实现性能提升,而不是jffs2 的sync 性同步写入
- 能处理data corruptions, flash bit flip, dynamically bad blocks
1. index problem
block device 与flash device最大的不同在于”in placed updates”. Flash 设备不能直接写,除非进行了Erase 操作。
因此, ubifs 采用“out-of-place updates”, 只在必要的时候(有其他的sector 需要更新时)才将数据真正写入flash。
ubifs 使用log-structured design 记录这些更新。另一方面,这样也可以减少flash的erase cycles。
问题: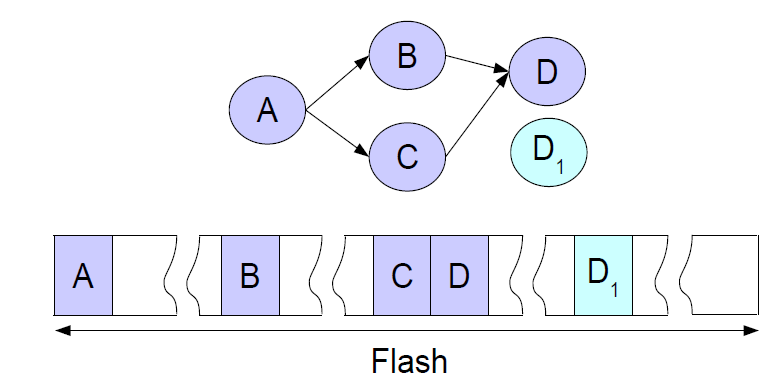
A 引用了B, A引用了C, B,C 引用了D, 现在D 使用了”out-of-place updates” 更新到了D1, 怎么保证B, C 是引用的最新的D1。
1.2. wandering tree
wandering tree 可以解决如上问题。
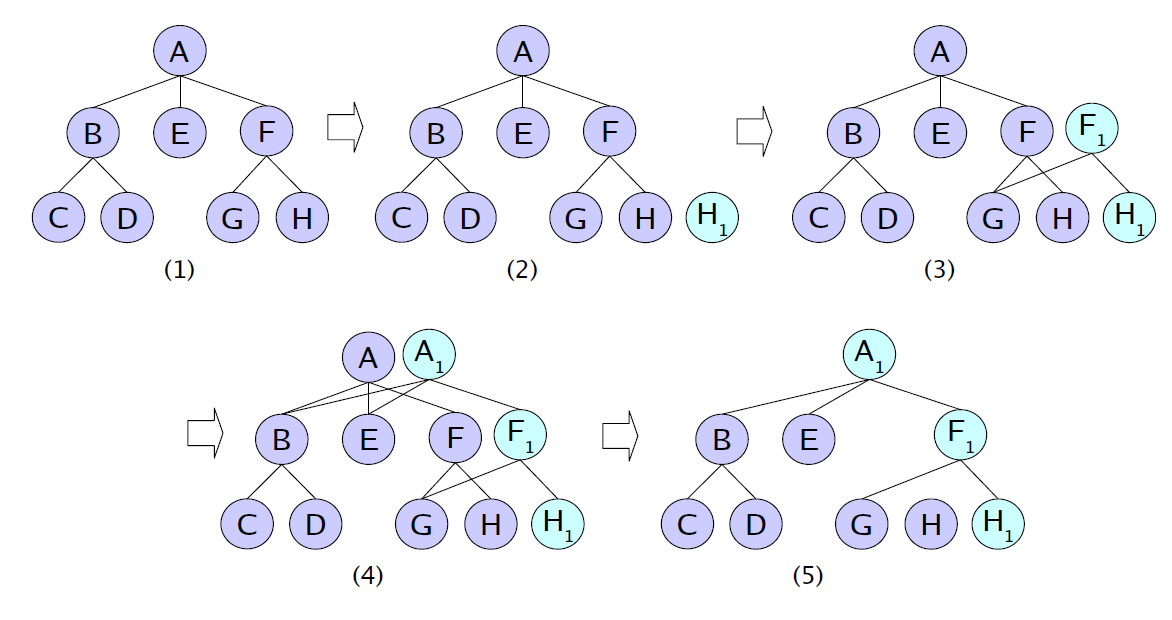
假设需更新H1, 涉及到的F, A也需更新。
any tree may be called ”wandering tree” if any update in the tree requires updating parent nodes up
to the root. For example, it makes sense to talk about wandering Red-Black trees or wandering B+-trees and so forth.
1.3. B+ tree
ubifs 采用B+ tree 多路平衡搜索二叉树。只有叶子节点包含data,非叶子节点只包含keys 和links。 B+ tree 广泛用于
block devices上。
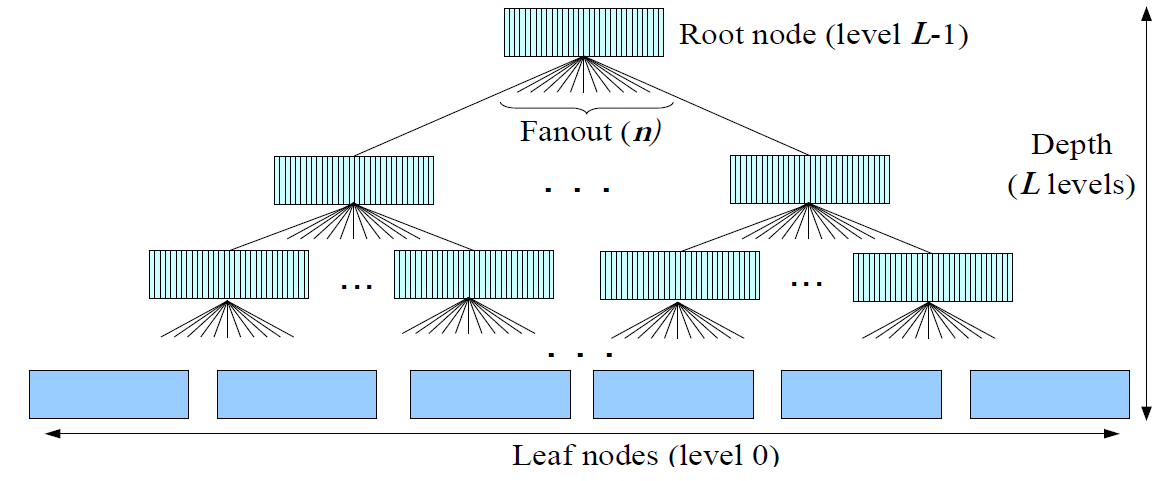
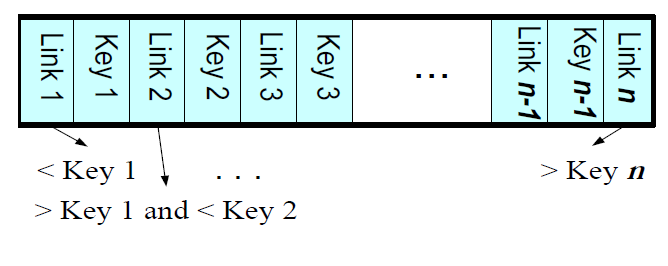
non-leaf node 包含如下:
- 增序的keys
- 指向leaf node 或non-leaf node 的 links
当有新的insert 或者remove 发生时, B+ tree 将会重新re-balancing, node 的删除与合并可能发生。
2. indexing in ubifs
UBIFS 参考了Reiser4 file system. 所有的 fs objects(inodes, files, directory entries, extended attributes, etc) 都包含在一个large B+ tree。
他们的keys 可能如下:
- file data key: {inode number, offset};
- directory entry key: {parent directory inode number, direntry name hash};
- extended attribute key: {target inode number, xattr name hash} and the like
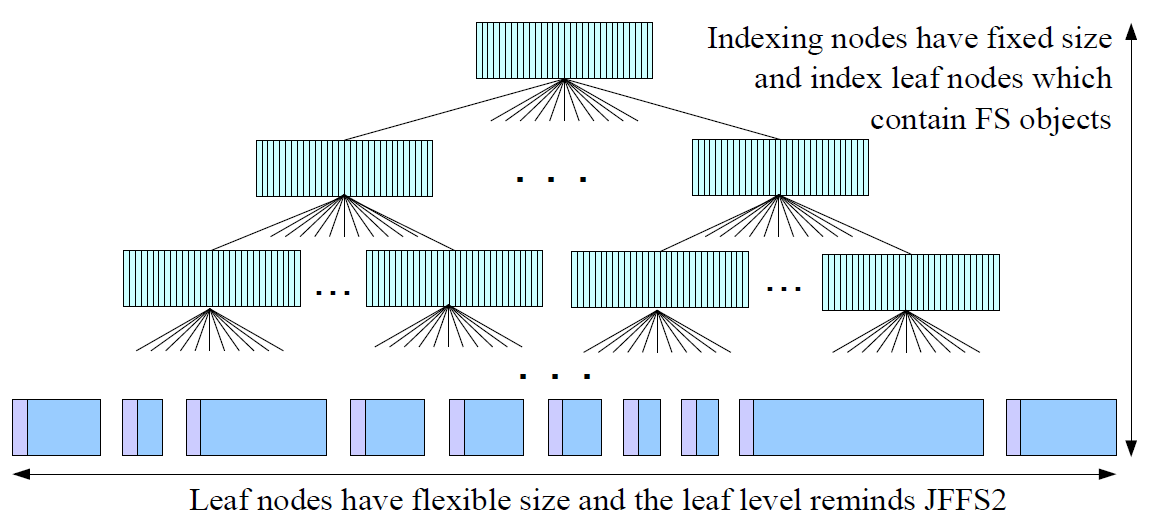
non-leaf node 被称为indexing nodes, 只包含indexing 信息。
leaf node 有flexible size, 他对应与flash 的sector size, 例如 512, 2K 等(与Flash 的硬件特性有关)。
leaf node 包含:
- header (describes the node data and information like the key of the node, the length, and the like)
- data (some file system data)
leaf nodes 与indexing nodes 是分开存储在不同的Eraseblock上。

ubifs indexing approach 优点:
- The leaf nodes may be compressed
- In case of corruptions of the indexing information, it is possible to re-create it by scanning leaf nodes’ headers
- There is a clear separation between data and indexing information. indexing and data may be cached separately
3. the journal
ubifs tree 本身是B+ tree and wandering tree. 如果某些nodes 需要更新,就update flash data, 这并不理想。
journal provides a mechanism to avoid this. 因此, ubifs 中有index and journal B+ tree.
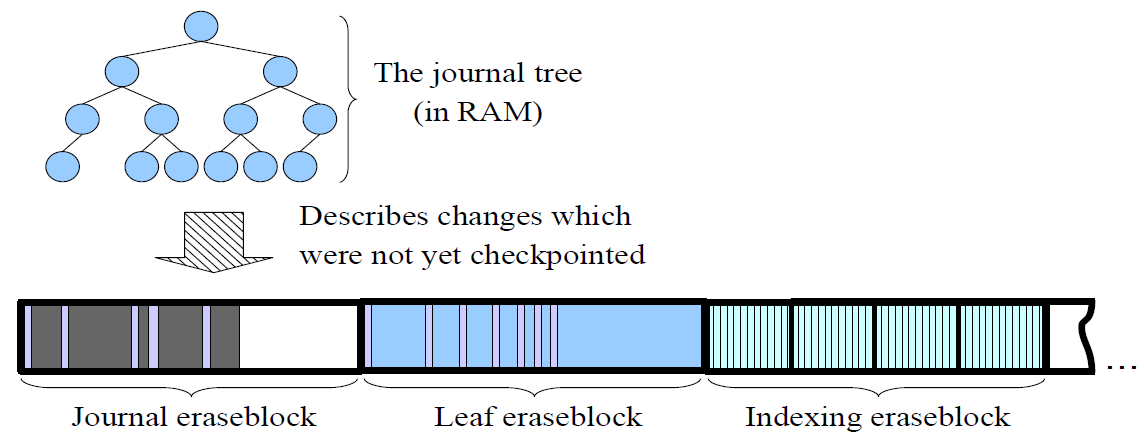
journal 有位置不固定的journal eraseblocks组成。
create
journal tree 在ubifs mount 时根据Flash 上journal eraseblocks创建于RAM 中 。
Write
在有更新时,相应的leaf nodes 被写入到journal tree, 而相应的indexing nodes 不更新。
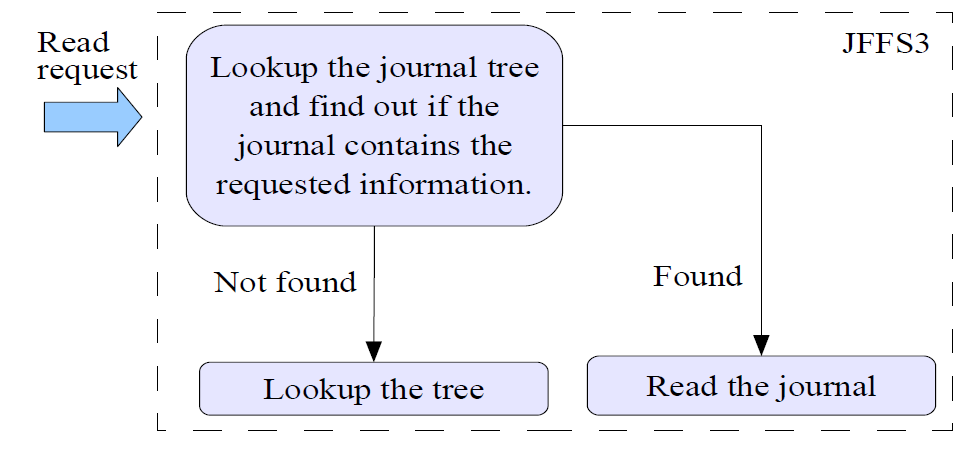
read
首先查询是否在journal tree, 存在则从该树read,否则执行常规tree lookup.
update
journal tree 在full 或者在适当的时机是会checkpointed。在journal tree 中记录的信息与相应的indexing nodes 将会被写入到Flash 中。
checkpointed journal eraseblocks 会被当做leaf eraseblocks, 新的journal eraseblocks 会被UBIFS 通过 wear-leveling 算法选出(这是journal eraseblocks 不固定的产生)。
另外,journal tree 越大,可能会达到更好的性能, 但是在mount 时创建tree耗费的时间也会变长,这需要选取平衡在mount time and journal tree size.
4. the superblock
superblock 包含描述整个fs 的数据结构。传统的fs 可以存储superblock 在固定的位置, 但是Flash 由于badblock, 寿命的因素(wear-leveling)的原因,
导致superblock 不能存储在固定位置。
ubifs 将superblock 划分为两种类型:
- static superblock, 不会被ubifs 改变,可以被external user-level tools 更改(例如name, volume size,compression type等)。
- superblock, 包含动态数据,时常被更改,使用wear-leveling 算法挑选。
ubifs 前3个good eraseblock 如下安排:
.———————————————————————————–.
| static superblock(1 eraseblock) | anchor area (2 eraseblocks) |
`———————————————————————————–.
2 eraseblocks anchor area 是为了确保数据的安全性在unclean reboots时。
anchor area 与 dynamic superblock 结构如下:

为了使superblock 使用上wear-leveling。superblock 的管理方法如下:
- 在super eraseblock 上更新数据, 如果写满了则使用wear-leveling 选出新的eraseblock, 同时更新chain eraseblock2 中sector
- 如果chain eraseblock2 中sector写满, 则pick up 新的eraseblock 作为chain eraseblock2,并记录信息在chain eraseblock1 中sector
- 以此类推记录数据到Anchor area 中的sector。
super eraseblock sector -> chain eraseblock2 sector -> chain eraseblock1 sector -> anchor area sector
Search 则是存储的相反顺序了。