任务的调度可以分为两步:
- 使用某种算法选出下一个将要运行的任务
- swtich 到该任务并执行
本篇文章主要讲任务是怎样切换。
1. 调度时机
调度可以分为主动或者被动。 主动态的有:
- IO R/W 时发生的阻塞
- user space 进程主动使用sleep()或exit() , 或者kernel space 驱动等使用schedule() 进行状态切换
- 进程在等待signal, mutex 资源时
被动态触发调度的有:
- tick clock, 进程运行时间片用完
- fork() 新进程时,可能引起被动调度
- 从中断、异常及系统调用状态结束返回时,ret_from_sys_call() 判断调度标志是否需要转换,这样考虑是为了效率,在内核态就将需要状态转换
- 若支持preempt,则从抢占模式退出时
2. flow
入口都是从schedule()。 在前期判断当前运行的task 是否需要将block data 进行flush 操作。关闭抢占,进行调度。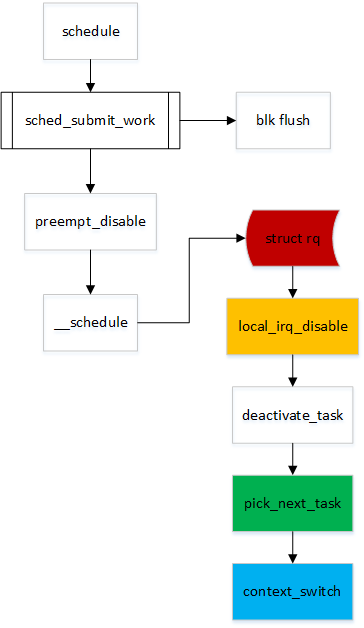
1 | /* linux-4.9.198 src */ |
linux 使用struct rq 保存local runqueue,使用smp_processor_id() 读取当前运行CPU ID, 并进一步得到local rq。
之后关闭local cpu irq 避免local 中断影响,将当前task 从rq 队列中remove, 通过合适的算法从rq 中pick next task, 最后使用context_switch 切换到next task 上运行。
1 | static void __sched notrace __schedule(bool preempt) |
2.1. pick next task
在另一篇中讲解进程调度算法。
FixMe
kernel_process_management
2.2. context_switch
1 | static __always_inline struct rq * |
在此之前,我们需要有一个认知,进程切换的情况可能是:
- 普通进程 -> 普通进程
- 普通进程 -> 内核进程/thread
- 内核进程 -> 普通进程
- 内核进程 -> 内核进程
ps: 普通进程 指user space 进程。
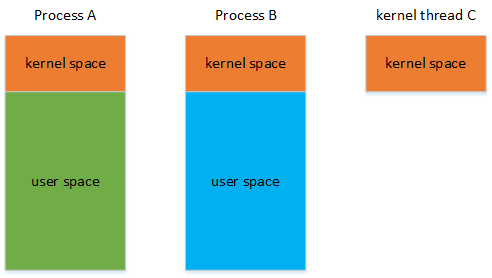
以32 bit ARM 为例, 普通进程之间0~3G 独立虚拟空间, 3~4G 共享内核地址空间。因此,当next 为内核进程时,我们可以使用pre 的active_mm 空间,内核进程100% 不会使用到0~3G 的虚拟空间,他只需要的是3~4G 的内核空间的地址转换表。
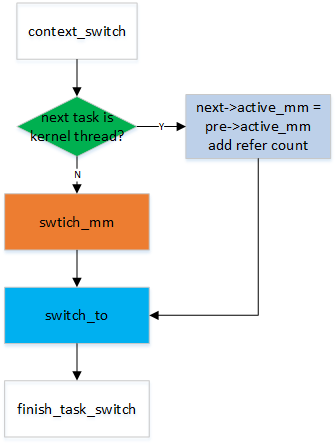
那主要分为两大类:next 是否为kernel thread。若是,next 借助pre->active_mm(减少分配mm, 映射上等时间的浪费), 反之,则需要进行switch_mm。 当然,kernel 也考虑到了如果上次也为kernel thread 情况如下, context_switch 中就有了:1
2
3
4if (!prev->mm) {
prev->active_mm = NULL;
rq->prev_mm = oldmm;
}
那pre 应该将active_mm 的引用数减少,以便回收。在之后的finish_task_switch() 就有mmdrop()的尝试回收:1
2
3
4
5
6
7
8
9
10
11
12
13
14static struct rq *finish_task_switch(struct task_struct *prev)
__releases(rq->lock)
{
struct mm_struct *mm = rq->prev_mm;
rq->prev_mm = NULL;
if (mm)
mmdrop(mm);
...
}
static inline void mmdrop(struct mm_struct *mm)
{
if (unlikely(atomic_dec_and_test(&mm->mm_count)))
__mmdrop(mm);
}
2.2.1. switch_mm/switch_mm_irqs_off
switch_mm 把虚拟内存从一个进程映射切换到新进程中,
1 | static inline void |
在check_and_switch_context() 函数中有考虑是否CPU 是否支持TLB ASID (address space ID)。CPU中往往设计了TLB和Cache。Cache为了更快的访问main memory中的数据和指令,而TLB是为了更快的进行地址翻译而将部分的页表内容缓存到了Translation lookasid buffer中,避免了从main memory访问页表的过程。 进程A,B 在kernel space 可以共享,但是各自的虚拟空间user space 则不同,TLB 势必要进行更新,那怎么才能既保证正确性有保证效率呢?ARM 中引入了TLB,ASID, VMID 来支持区别application, virtual machine 的情况。switch_mm 时flush 掉pre->active_mm, 通过global 标志来区别kernel space or user space, 若为global entry 则无需flush。
但是ASID 能记录的ID 数目是要受限于HW 的bits。在arm32 上是8 bit, 意味着能记录256 个ID。当系统中各个cpu的TLB中的asid合起来不大于256个的时候,系统正常运行,一旦超过256的上限后,我们将全部TLB flush掉,并重新分配ASID,每达到256上限,都需要flush tlb并重新分配HW ASID。具体分配ASID代码如下:
1 | /* linux-4.9.198/arch/arm/mm/context.c */ |
上面函数考虑了如下几种情况:
- 若(asid = atomic64_read(&mm->context.id)) != 0,说明此mm 已经分配过software asid(generation+hw asid)了,因初始值为0。那么new context不过就是将software asid中的旧的generation更新为当前的generation而已。
- 若asid == 0, 则需要分配一个新的HW ID
- 若能找到空闲HW ID则返回software asid(当前generation + 新分配hw asid)
- 若不能找到,多个CPU 上的old generation 需要被flush 掉, 标记tlb_flush_pending。
有了上面的认知后,在看下面的代码就比较明了。最终,会调用到cpu_switch_mm()1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29void check_and_switch_context(struct mm_struct *mm, struct task_struct *tsk)
{
unsigned long flags;
unsigned int cpu = smp_processor_id();
u64 asid;
asid = atomic64_read(&mm->context.id);
if (!((asid ^ atomic64_read(&asid_generation)) >> ASID_BITS)
&& atomic64_xchg(&per_cpu(active_asids, cpu), asid))
goto switch_mm_fastpath;
/* Check that our ASID belongs to the current generation. */
asid = atomic64_read(&mm->context.id);
if ((asid ^ atomic64_read(&asid_generation)) >> ASID_BITS) {
asid = new_context(mm, cpu);
atomic64_set(&mm->context.id, asid);
}
if (cpumask_test_and_clear_cpu(cpu, &tlb_flush_pending)) {
local_flush_bp_all();
local_flush_tlb_all();
}
atomic64_set(&per_cpu(active_asids, cpu), asid);
cpumask_set_cpu(cpu, mm_cpumask(mm));
switch_mm_fastpath:
cpu_switch_mm(mm->pgd, mm);
}
汇编级的代码主要做了设置context ID register, translation table base0 register.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29/*
* cpu_v7_switch_mm(pgd_phys, tsk)
* Set the translation table base pointer to be pgd_phys
* - pgd_phys - physical address of new TTB
*
* It is assumed that:
* - we are not using split page tables
*
* Note that we always need to flush BTAC/BTB if IBE is set
* even on Cortex-A8 revisions not affected by 430973.
* If IBE is not set, the flush BTAC/BTB won't do anything.
*/
ENTRY(cpu_v7_switch_mm)
mmid r1, r1 @ get mm->context.id
ALT_SMP(orr r0, r0, #TTB_FLAGS_SMP)
ALT_UP(orr r0, r0, #TTB_FLAGS_UP)
mrc p15, 0, r2, c13, c0, 1 @ read current context ID
lsr r2, r2, #8 @ extract the PID
bfi r1, r2, #8, #24 @ insert into new context ID
#endif
mcr p15, 0, r1, c13, c0, 1 @ set context ID
isb
mcr p15, 0, r0, c2, c0, 0 @ set TTB 0
isb
#endif
bx lr
ENDPROC(cpu_v7_switch_mm)

2.2.2. switch_to
保存prev 通用寄存器和堆栈等, 恢复next 以便切换后运行。
1 |
|
先从prev thread_info offset #TI_CPU_SAVE 的 struct cpu_context_save, 并将当前r4 ~ r10, r12 ~ r15 进行保存。接着从next 同样的offset struct cpu_context_save 恢复寄存器。
1 | struct thread_info { |
Reference
进程切换分析(1):基本框架
进程切换分析(2):TLB处理
进程切换分析(3):同步处理
Linux内核浅析-进程调度时机和过程